查看网址
我也看看我三个qq的时间:
7279915
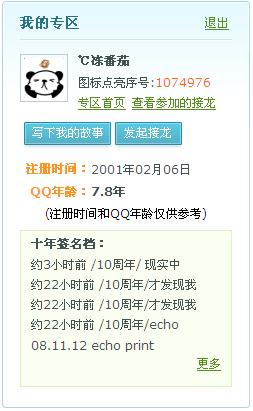
50130089

1903710
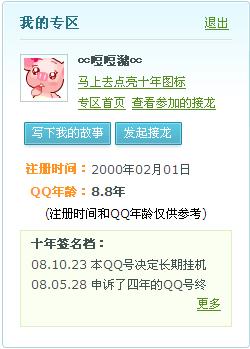
还一个我妹的,号是 380715XX
(8位的,03年申请到的,貌似运气非常好,当时用qq申请精灵申请的!一般来说01年末申请的号就是9位的了)
查看网址
我也看看我三个qq的时间:
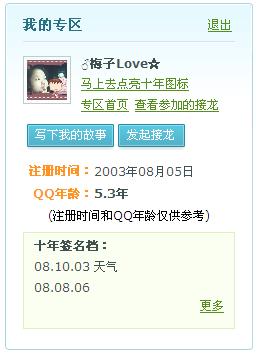
7279915
50130089
1903710
还一个我妹的,号是 380715XX
(8位的,03年申请到的,貌似运气非常好,当时用qq申请精灵申请的!一般来说01年末申请的号就是9位的了)
命令全部在命令模式下输入 (就是记得输命令时按下ESC键)
保存文件 :w (注意,前面有:)
强制保存文件 :w!
退出文件但不保存 :q
强制奶出文件但不保存 :q!
保存并退出 :wq (同理,如果是强制的话,加!)
==================================
在光标所在行插入新行 o (注意,不是零,是字母o)
在光标前面插入字符 i
在光标后面输入字符 a
删除一行 dd
删除光标所在的字符 x
转到具体的一行 10gg 或是 :10 (10为行号)
转个首行 gg
转个尾行 shift+g
清空全部内容 :%d
清空光标所在行及下面全部行的内容 dG (注意大小写)
撤销上一步操作 u
重做上一步操作 ctrl+r
搜索查找字符 ?str 或 /str (str表示要查找的字符)
===========================================
这些是最基本的了,还有像替换之类的比较复杂的就找找vi的全部命令看看
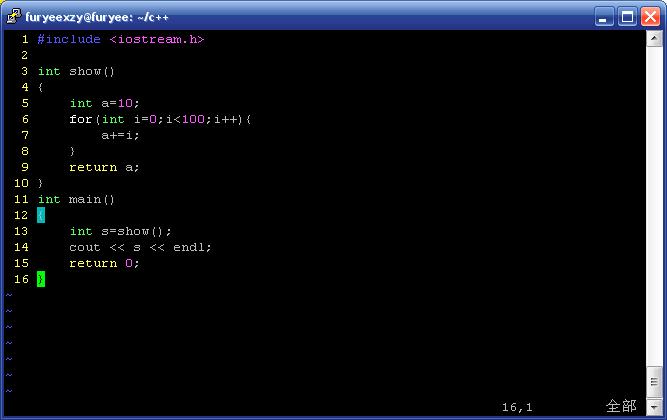
1、安装vim
colorscheme elflord
"colorscheme darkblue
"colorscheme evening
"colorscheme murphy
"colorscheme torte
"colorscheme desert
这些事提供的一些配色方案,自选一种就很漂亮了~
从网上下载了最新的 QQWry.Data 库文件,首先碰到的一个问题是解析这个文件。根据网上的资料(LuamaQQ作者写的日志),根据自己的摸索,总结出了此文件的内容结构,以及解读方式。
一、文件结构
文件主要分三个结构
1、文件头,8个字节;
2、数据记录区,不定长度;
3、索引区,长度为 7 的整数倍;
二、文件头
文件头的8个字节分两部分,每个部分4个字节,分别指定了索引区的开始地址和结束地址。所以可以通过两个地址的差值 除 7 后 加 1 可以计算出总的记录数。
二、记录区
记录区的数据需要通过索引区的数据来获得各个数据的起始位置;本区数据记录了IP地址的结束地址和地区字符串;所有地区字符串都以 0x00 为结束。
三、索引区
检索IP对应的地区,关键就是找到IP起始地址对应的索引内容。一个IP索引数据包含7个字节,前4个字节是IP地址起始值,后3个字节是对应的IP数据记录在文件内的偏移地址;IP数据记录中,前 4 个字节是IP结束地址;紧跟的数据有两种模式: 0x01 模式 和 0x02 模式。
0x01模式,即在IP数据的第5个字节是 0x01,则在后面的 3 个字节是国家地区数据的偏移地址;国家地区数据包括国家和地区这两个字符串。即
—————————————————————
4字节 | 3字节 重定向 0x NN NN NN -> 国家地区数据的文件偏移地址
—————————————————————
0x02模式,即在IP数据的第5个字节是 0x02,则在后面的 3 个字节是国家数据的偏移地址,地区数据是再往后的字符串,以 0x00 截至。即
—————————————————————————–
4字节 | 3字节 重定向 0x NN NN NN -> 国家数据的文件偏移地址 | 地区字符串 | 0x00
—————————————————————————–
对于 0x01 模式所得到的 国家地区数据中,它可能又带有一个重定向结构,即
————————————–
国家字符串 | 0x00 | 地区字符串 | 0x00
————————————–
或
————————————————————————-
国家字符串 | 0x00 | 0x02 | 3字节 0x NN NN NN -> 地区字符串的文件偏移地址
————————————————————————-
对于前一种情况,比较简单,直接读出两个字符串数据就可以了;对于后一种情况,需要再次重定向到地区字符串的偏移地址,然后读取到 0x00 为字符串结尾。
对于这种采取地址映射实际字符串值的方式,主要作用是避免重复记录字符串值。在整个IP地址库文件中,有太多相同字符串记录了,采用 3 字节的映射地址要比重复记录字符串值节省太多空间了。