因为十一在南昌买了房子,所以在常州的收入已无法满足资金上的要求了,另最关键的是目前常州公司在我从事的网站方面没有一个好的前景,所以打算离开。
新找的东家是上海我友网 www.woyo.com 研发部开发工程师,下周去上海了,先准备找好房子。然后25号去办理入职手续了!希望在新的公司先是能学到更多,同时希望公司能发展壮大!
因为十一在南昌买了房子,所以在常州的收入已无法满足资金上的要求了,另最关键的是目前常州公司在我从事的网站方面没有一个好的前景,所以打算离开。
新找的东家是上海我友网 www.woyo.com 研发部开发工程师,下周去上海了,先准备找好房子。然后25号去办理入职手续了!希望在新的公司先是能学到更多,同时希望公司能发展壮大!
购买的是buyvm.net 的15美金1年的计划,经过测试速度还是不错的。
目前先把blog搬到新的vps中,现在vps安装的是lnmp环境,这样可以更省内存!
1.认识及了解MongoDB
MongoDB 是一个面向集合的,模式自由的文档型数据库.
面向集合, 意思是数据被分组到若干集合,这些集合称作聚集(collections). 在数据库里每个聚集有一个唯一的名字,可以包含无限个文档. 聚集是RDBMS中表的同义词,区别是聚集不需要进行模式定义.
模式自由, 意思是数据库并不需要知道你将存入到聚集中的文档的任何结构信息.实际上,你可以在同一个聚集中存储不同结构的文档.
文档型, 意思是我们存储的数据是键-值对的集合,键是字符串,值可以是数据类型集合里的任意类型,包括数组和文档. 我们把这个数据格式称作 "[BSON]" 即 "Binary Serialized dOcument Notation."
集 文档数据库,键值对存储和关系型数据库的优点于一身.
MongoDB (名称来自"humongous") 是一个可扩展的,高性能,开源,模式自由,面向文档的数据库.使用C++编写,MongoDB特点:
* 面向文档存储(类JSON数据模式简单而强大)
* 动态查询
* 全索引支持,扩展到内部对象和内嵌数组
* 查询记录分析
* 快速,就地更新
* 高效存储二进制大对象 (比如照片和视频)
* 复制和故障切换支持
* Auto- Sharding自动分片支持云级扩展性
* MapReduce 支持复杂聚合
* 商业支持,培训和咨询
所 谓"面向集合"(Collenction-Orented),意思是数据被分组存储在数据集中, 被称为一个集合(Collenction)。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库 (RDBMS)里的表(table),不同的是它不需要定义任何 模式(schema)。
模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同 结构的文件存储在同一个数据库里。
存储在集合中的文档,被存储为键-值对的形式。键用于唯一标 识一个文档,为字符串类型,而值则可以是各种复杂的文件类型。我们称这种存储形式为 BSON(Binary Serialized dOcument Format)。
哪些公司在用MongoDB
sourceforge、github等。
MongoDB 有个缺点,存储的数据占用空间过大。
MongoDB的主要目标是在键/值存储方式(提供了高性能和高度伸缩性)以及传统的RDBMS系统 (丰富的功能)架起一座桥梁,集两者的优势于一身。根据官方网站的描述,Mongo 适合用于以下场景:
* 网站数据:Mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
* 缓存:由于性能很高,Mongo也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源过载。
* 大尺寸,低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
* 高伸缩性的场景:Mongo非常适合由数十或数百台服务器组成的数据库。Mongo的路线图中已经包含对MapReduce引擎的内置支持。
* 用于对象及JSON数据的存储:Mongo的BSON数据格式非常适合文档化格式的存储及查询。
自然,MongoDB的使用也会有 一些限制,例如它不适合:
* 高度事务性的系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
* 传统的商业智能应用:针对特定问题的BI数据库会对产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
* 需要SQL的问题
Via:http://www.infoq.com/cn/news/2009/09/mongodb
性能
在 我的使用场合下,千万级别的文档对象,近10G的数据,对有索引的ID的查询不会比mysql慢,而对非索引字段的查询,则是全面胜出。 mysql实际无法胜任大数据量下任意字段的查询,而mongodb的查询性能实在让我惊讶。写入性能同样很令人满意,同样写入百万级别的数 据,mongodb比我以前试用过的couchdb要快得多,基本10分钟以下可以解决。补上一句,观察过程中mongodb都远算不上是CPU杀手。
Via:http://www.wentrue.net/blog/?p=772
2. 安装及配置
说明,MongoDB下载然后解压缩以后就可以直接使用了,不需要编译及安装。
在页面http://www.mongodb.org/display/DOCS/Downloads中找到适合于你所在操作系统的MongoDB版本。
[root@CentOS_Test_Server software]# wget http://downloads.mongodb.org/linux/mongodb-linux-i686-1.4.2.tgz
/home/software是存放软件的目录,把mongodb解压到其它的目录下
直接解压缩到目录/usr/local/webserver 下。
[root@CentOS_Test_Server software]# tar zxvf mongodb-linux-i686-1.4.2.tgz -C /usr/local/webserver/
[root@CentOS_Test_Server webserver]# ls
eaccelerator_cache mongodb-linux-i686-1.4.2 mysql nginx php squid
将目录改名,方便以后使用方便。
[root@CentOS_Test_Server webserver]# mv mongodb-linux-i686-1.4.2/ mongodb
[root@CentOS_Test_Server software]# cd /usr/local/webserver/mongodb
[root@CentOS_Test_Server mongodb]# ls
bin GNU-AGPL-3.0 include lib README THIRD-PARTY-NOTICES
直接查看README文件的内容,里面的说明对使用MongoDB也会很有帮助。
[root@CentOS_Test_Server mongodb]# more README
MongoDB
=======
Welcome to MongoDB!
Package Contents
—————-
bin/mongod – MongoDB server
bin/mongo – MongoDB client
bin/mongodump – MongoDB dump tool – for backups, snapshots, etc..
bin/mongorestore – MongoDB restore a dump
bin/mongoexport – Export a single collection to test (json,csv)
bin/mongoimportjson – Import a json file into a collection
bin/mongofiles – Utility for putting and getting files from MongoDB gridfs
Useful Resources
—————-
MongoDB Website
* http://www.mongodb.org/
Documentation
* http://www.mongodb.org/display/DOCS/Documentation
MongoDB Maillists & IRC
* http://www.mongodb.org/display/DOCS/Community
如果直接输入命令./mongod,则 MongoDB的数据直接保存在/data/db目录(windows操作系统下是c:\data\db目录), 默认监听在27017端口。
如 果你启动MongoDB时没有指定任何参数,同时目录/data/db也不存在,则会报错。
[root@CentOS_Test_Server bin]# ./mongod –help | grep fork
–fork fork server process
[root@CentOS_Test_Server bin]# ./mongod –help | grep dbpath
–dbpath arg (=/data/db/) directory for datafiles
dbpath
–fastsync indicate that this instance is starting from a dbpath
[root@CentOS_Test_Server bin]# ./mongod –help | grep port
–port arg specify port number
–source arg when slave: specify master as <server:port>
运 行./mongod –help命令时mongodb提示了一下,也就是32位操作系统只支持最大2G的文件,如果你的应用中数据量很大,超过了2G,推荐安装64位的操作 系统。2Gb or Not 2Gb – File limits说明 了为什么32位操作系统只支持最大2G的文件。
[root@CentOS_Test_Server bin]# ./mongod –help | more
** NOTE: when using MongoDB 32 bit, you are limited to about 2 gigabytes of data
** see http://blog.mongodb.org/post/137788967/32-bit-limitations for more
创建目录保存MongoDB数据的目录。
[root@CentOS_Test_Server bin]# mkdir /home/mongodb_data
启动MongoDB
[root@CentOS_Test_Server bin]# ./mongod –fork –dbpath=/home/mongodb_data –logpath /home/mongodb_data/mongodb.log –logappend
all output going to: /home/mongodb_data/mongodb.log
forked process: 3799
[root@CentOS_Test_Server bin]# ps aux | grep mongo
root 3799 0.0 0.7 59032 2008 ? Ssl 16:59 0:00 ./mongod –fork –dbpath=/home/mongodb_data –logpath /home/mongodb_data/mongodb.log –logappend
root 3825 0.0 0.2 3920 628 pts/1 S+ 17:00 0:00 grep mongo
[root@CentOS_Test_Server bin]# netstat -antl | grep 27017
tcp 0 0 0.0.0.0:27017 0.0.0.0:* LISTEN
停止 MongoDB的进程时不能用kill -9,而最好用kill -15,否则会导致出现问题。
同时会自动启动一个端口为28017的服务,此服务用于监控MongoDB的状态
[root@CentOS_Test_Server bin]# netstat -a | grep 28017
tcp 0 0 *:28017 *:* LISTEN
用curl可以在启动MongoDB所在的服务器上面直接访问, 如果想从其它的访问访问此服务,则必须在防火墙上开放28017端口。
[root@CentOS_Test_Server bin]# curl localhost:28017
<html><head><title>mongodb CentOS_Test_Server:27017 </title></head><body><h2>mongodb CentOS_Test_Server:27017 </h2><p>
<pre>db version v1.4.2, pdfile version 4.5
git hash: 53749fc2d547a3139fcf169d84d58442778ea4b0
sys info: Linux domU-12-31-39-01-70-B4 2.6.21.7-2.fc8xen #1 SMP Fri Feb 15 12:39:36 EST 2008 i686 BOOST_LIB_VERSION=1_37
…..
我在服务器上打开了28017端口,不知道为什么 在其它的电脑上面输入地址http://192.168.1.111:28017/无法访问,暂时不知道是什么原因。
[root@CentOS_Test_Server bin]# iptables -A RH-Firewall-1-INPUT -p tcp -m state –state NEW -m tcp –dport 28017 -j ACCEPT
[root@CentOS_Test_Server bin]# /etc/init.d/iptables save
Saving firewall rules to /etc/sysconfig/iptables: [ OK ]
更多MongoDB启动的问题,请移步 Starting and Stopping Mongo,http://www.mongodb.org/display/DOCS/Starting+and+Stopping+Mongo
3. 测试
[root@CentOS_Test_Server bin]# ls
运行MongoDB下面bin目录下的mongo命 令,就可以进入MongoDB的shell界面了,跟MySQL有点类似,输入命令help,其它的看帮助基本上就明白了。
mongo mongod mongodump mongoexport mongofiles mongoimport mongorestore mongos mongosniff mongostat
[root@CentOS_Test_Server bin]# ./mongo
MongoDB shell version: 1.4.2
url: test
connecting to: test
type "help" for help
> help
HELP
show dbs show database names
show collections show collections in current database
show users show users in current database
show profile show most recent system.profile entries with time >= 1ms
use <db name> set curent database to <db name>
db.help() help on DB methods
db.foo.help() help on collection methods
db.foo.find() list objects in collection foo
db.foo.find( { a : 1 } ) list objects in foo where a == 1
it result of the last line evaluated; use to further iterate
在MongoDB中,在使用Database或Collection前不需要提前创建,在使用的过程中会 自动创建。
更多的有关信息请移步MongoDB Tutorial。
a.测试一
我们来测试一下就明白了
> use recommender //在此之前我可从来没有创建过数据库recommender
> a={name: "caihuafeng"} //也就是json对象,大家看起来是不是非常熟悉
{ "name" : "caihuafeng" }
> b={website: "1616.net"}
{ "website" : "1616.net" }
> db.data.save(a) //在此之前我可没有创建过表data,在数据库recommender的表data中保存数据a,可以理解为往MySQL的表data中添加一条记录
> db.data.save(b) //在数据库recommender的表data中保存数据b,可以理解为往MySQL的表data中添加一条记录
> db.data.find() //显示数据库recommender的表data中的所有数据
{ "_id" : ObjectId("4bee745a0863b1c233b8b7ea"), "name" : "caihuafeng" }
{ "_id" : ObjectId("4bee745f0863b1c233b8b7eb"), "website" : "1616.net" }
> show collections //显示数据库recommender中的所有表(collection在这里相当于MySQL中的表)
data
system.indexes //这个表是自动创建的
显示数据库recommender中website为1616.net的记录,相当于MySQL中的 SELECT * FROM data WHERE website='1616.net';
> db.data.find({website:"1616.net"})
{ "_id" : ObjectId("4bee745f0863b1c233b8b7eb"), "website" : "1616.net" }
显示 数据库recommender中name为caihuafeng的记录,相当于MySQL中的SELECT * FROM data WHEREname ='caihuafeng';
> db.data.find({name:"caihuafeng"})
{ "_id" : ObjectId("4bee745a0863b1c233b8b7ea"), "name" : "caihuafeng" }
MongoDB 比其它的关系型数据库更加灵活,因为每一行的记录都可以有不同的结构,而且表的结构根本上不需要提前创建,灵活极了。
b.测试二
发现就是在写js代码,然后跟数据库结合起来了。
> for (var i = 1; i <= 10; i++) db.data.save({"x":6, "name":"caihuafeng" + i});
> db.data.find();
{ "_id" : ObjectId("4bee745a0863b1c233b8b7ea"), "name" : "caihuafeng" }
{ "_id" : ObjectId("4bee745f0863b1c233b8b7eb"), "website" : "1616.net" }
{ "_id" : ObjectId("4bee804ba23d558eb6687117"), "x" : 6, "name" : "caihuafeng1" }
{ "_id" : ObjectId("4bee804ba23d558eb6687118"), "x" : 6, "name" : "caihuafeng2" }
{ "_id" : ObjectId("4bee804ba23d558eb6687119"), "x" : 6, "name" : "caihuafeng3" }
{ "_id" : ObjectId("4bee804ba23d558eb668711a"), "x" : 6, "name" : "caihuafeng4" }
{ "_id" : ObjectId("4bee804ba23d558eb668711b"), "x" : 6, "name" : "caihuafeng5" }
{ "_id" : ObjectId("4bee804ba23d558eb668711c"), "x" : 6, "name" : "caihuafeng6" }
{ "_id" : ObjectId("4bee804ba23d558eb668711d"), "x" : 6, "name" : "caihuafeng7" }
{ "_id" : ObjectId("4bee804ba23d558eb668711e"), "x" : 6, "name" : "caihuafeng8" }
{ "_id" : ObjectId("4bee804ba23d558eb668711f"), "x" : 6, "name" : "caihuafeng9" }
{ "_id" : ObjectId("4bee804ba23d558eb6687120"), "x" : 6, "name" : "caihuafeng10" }
> var cursor = db.data.find();
> while (cursor.hasNext()) {print(tojson(cursor.next()))};
{ "_id" : ObjectId("4bee745a0863b1c233b8b7ea"), "name" : "caihuafeng" }
{ "_id" : ObjectId("4bee745f0863b1c233b8b7eb"), "website" : "1616.net" }
{
"_id" : ObjectId("4bee804ba23d558eb6687117"),
"x" : 6,
"name" : "caihuafeng1"
}
{
"_id" : ObjectId("4bee804ba23d558eb6687118"),
"x" : 6,
"name" : "caihuafeng2"
}
{
"_id" : ObjectId("4bee804ba23d558eb6687119"),
"x" : 6,
"name" : "caihuafeng3"
}
{
"_id" : ObjectId("4bee804ba23d558eb668711a"),
"x" : 6,
"name" : "caihuafeng4"
}
{
"_id" : ObjectId("4bee804ba23d558eb668711b"),
"x" : 6,
"name" : "caihuafeng5"
}
{
"_id" : ObjectId("4bee804ba23d558eb668711c"),
"x" : 6,
"name" : "caihuafeng6"
}
{
"_id" : ObjectId("4bee804ba23d558eb668711d"),
"x" : 6,
"name" : "caihuafeng7"
}
{
"_id" : ObjectId("4bee804ba23d558eb668711e"),
"x" : 6,
"name" : "caihuafeng8"
}
{
"_id" : ObjectId("4bee804ba23d558eb668711f"),
"x" : 6,
"name" : "caihuafeng9"
}
{
"_id" : ObjectId("4bee804ba23d558eb6687120"),
"x" : 6,
"name" : "caihuafeng10"
}
> db.data.find({x:6}, {name:true}).forEach(function(x) {print(tojson(x));});
{ "_id" : ObjectId("4bee804ba23d558eb6687117"), "name" : "caihuafeng1" }
{ "_id" : ObjectId("4bee804ba23d558eb6687118"), "name" : "caihuafeng2" }
{ "_id" : ObjectId("4bee804ba23d558eb6687119"), "name" : "caihuafeng3" }
{ "_id" : ObjectId("4bee804ba23d558eb668711a"), "name" : "caihuafeng4" }
{ "_id" : ObjectId("4bee804ba23d558eb668711b"), "name" : "caihuafeng5" }
{ "_id" : ObjectId("4bee804ba23d558eb668711c"), "name" : "caihuafeng6" }
{ "_id" : ObjectId("4bee804ba23d558eb668711d"), "name" : "caihuafeng7" }
{ "_id" : ObjectId("4bee804ba23d558eb668711e"), "name" : "caihuafeng8" }
{ "_id" : ObjectId("4bee804ba23d558eb668711f"), "name" : "caihuafeng9" }
{ "_id" : ObjectId("4bee804ba23d558eb6687120"), "name" : "caihuafeng10" }
只取前3条记录,跟MySQL中的limit是类似的意思。
> db.data.find().limit(3);
{ "_id" : ObjectId("4bee745a0863b1c233b8b7ea"), "name" : "caihuafeng" }
{ "_id" : ObjectId("4bee745f0863b1c233b8b7eb"), "website" : "1616.net" }
{ "_id" : ObjectId("4bee804ba23d558eb6687117"), "x" : 6, "name" : "caihuafeng1"
4.MongoDB的主从复制(Master/Slave)配置及测试
主从复制有什么用呢? 比如,在两台服务器上分别部署了MongoDB,当一台出现了问题以后,另外一台可以接管服务,同时也起备份的作用。
MongoDB supports replication of data between servers for failover and redundancy.
MongoDB支持4种形式的复制,推荐用master/slave复制
* Master-Slave Replication
* Replica Pairs
* Replica Sets
* Limited Master-Master Replication
All else being equal, master/slave is recommended for MongoDB version 1.4.
与Master及Slave相关的帮助选项
[root@CentOS_Test_Server bin]# ./mongod –help | grep master
–master master mode
–source arg when slave: specify master as <server:port>
master ops to slave
[root@CentOS_Test_Server bin]# ./mongod –help | grep slave
–slave slave mode
–source arg when slave: specify master as <server:port>
–only arg when slave: specify a single database to replicate
–slavedelay arg specify delay (in seconds) to be used when applying
master ops to slave
–autoresync automatically resync if slave data is stale
启动MongoDB的Master服务
[root@CentOS_Test_Server bin]# ./mongod –fork –master –dbpath /home/masterdb/ –port 27018 –logpath /home/masterdb/mongodb.log –logappend
all output going to: /home/masterdb/mongodb.log
forked process: 11463
[root@CentOS_Test_Server bin]# ls /home/masterdb/
local.0 local.ns mongodb.log mongod.lock
启动MongoDB的Slave服务
[root@CentOS_Test_Server bin]# ./mongod –fork –slave –source localhost:27018 –autoresync –slavedelay 30 –dbpath /home/slavedb/ –port 27019 –logpath /home/slavedb/mongodb.log –logappend
all output going to: /home/slavedb/mongodb.log
forked process: 11848
[root@CentOS_Test_Server bin]# ls /home/slavedb/
local.0 local.ns mongodb.log mongod.lock _tmp
测试主从复制的功能
登录到 MongoDB的Master服务,插入一条数据
[root@CentOS_Test_Server bin]# ./mongo localhost:27018
MongoDB shell version: 1.4.2
url: localhost:27018
connecting to: localhost:27018/test
type "help" for help
> use recommender
switched to db recommender
> db.data.insert({name: "caihuafeng"})
> db.data.find()
{ "_id" : ObjectId("4beedc31e0e4fff2ce0295f6"), "name" : "caihuafeng" }
登录MongoDB的Slave服务,我们发现刚才保存到Master里面的数据已经复制到Slave了,这正是我们要看到的效果。
[root@CentOS_Test_Server bin]# ./mongo localhost:27019
MongoDB shell version: 1.4.2
url: localhost:27019
connecting to: localhost:27019/test
type "help" for help
> use recommender
switched to db recommender
> db.data.find()
{ "_id" : ObjectId("4beedc31e0e4fff2ce0295f6"), "name" : "caihuafeng" }
我们再看一下Slave服务上面产生的同步日志(/home/slavedb/mongodb.log)
Sun May 16 01:39:29 repl: from host:localhost:27018
Sun May 16 01:39:29 resync: dropping database recommender
Sun May 16 01:39:29 resync: cloning database recommender to get an initial copy
Sun May 16 01:39:29 allocating new datafile /home/slavedb/recommender.ns, filling with zeroes…
Sun May 16 01:39:29 done allocating datafile /home/slavedb/recommender.ns, size: 16MB, took 0.451 secs
Sun May 16 01:39:29 allocating new datafile /home/slavedb/recommender.0, filling with zeroes…
Sun May 16 01:39:31 done allocating datafile /home/slavedb/recommender.0, size: 64MB, took 1.397 secs
Sun May 16 01:39:31 allocating new datafile /home/slavedb/recommender.1, filling with zeroes…
Sun May 16 01:39:31 building new index on { _id: 1 } for recommender.data
Sun May 16 01:39:31 Buildindex recommender.data idxNo:0 { name: "_id_", ns: "recommender.data", key: { _id: 1 } }
…
为 了让MongoDB的主从服务可以自动启动,可以把下面的两条命令加到/etc/rc.local中。
/usr/local/webserver/mongodb/bin/mongod –fork –master –dbpath /home/masterdb/ –port 27018 –logpath /home/masterdb/mongodb.log –logappend
/usr/local/webserver/mongodb/bin/mongod –fork –slave –source localhost:27018 –autoresync –slavedelay 30 –dbpath /home/slavedb/ –port 27019 –logpath /home/slavedb/mongodb.log –logappend
附:
Sun May 16 00:59:47 waiting for connections on port 27018
Sun May 16 00:59:47 web admin interface listening on port 28018
Sun May 16 01:12:27 waiting for connections on port 27019
Sun May 16 01:12:27 web admin interface listening on port 28019
mongodb的端口为27017时,相应的web admin监听的端口为28017
mongodb 的端口为27018时,相应的web admin监听的端口为28018
mongodb的端口为27019时,相应的web admin监听的端口为28019
找到了一个规律,就是web admin的端口就是将mongodb的端口的第二位改为8,猜测应该是这样的。
http://www.mongodb.org/display/DOCS/Master+Slave
http://www.mongodb.org/display/DOCS/Replication
5.MongoDB的Sharding功能
MongoDB的Sharding功能将在1.6版本中出现,将在2010年7月份发布。
MongoDB has been designed to scale horizontally via an auto-sharding architecture. Auto-sharding permits the development of large-scale data clusters that incorporate additional machines dynamically, automatically accomodate changes in load and data distribution, and ensure automated failover.
Sharding will be production-ready in MongoDB v1.6, estimated to be released in July, 2010. In the meantime, an alpha version of sharding is available in the 1.5.x development branch. Please see the limitations page for progress updates and current restrictions.
http://www.mongodb.org/display/DOCS/Sharding
6. 总结
在 写这篇文章以前,我没有用过MongoDB, 以前简单的看过一些MongoDB的资料,只是有点了解,今天自己动手安装测试了一下以后对MongoDB有了更加深入一点的了解,再学习几天基本上就可 以在项目中实际使用了,比如MongoDB的读写性能也有必要再测试一下,虽然已经有不少人已经测试过了,证明MongoDB的读写性能比MySQL高, 不过功能没有MySQL强。
其实TC的Table Database也能实现一些关系型数据库的功能,也是值得深入研究一下的,其实以前我简单的研究过。Tokyo Cabinet及Tokyo Tyrant的命令行接口。
Table Database的特点是支持检索,支持多列字段,支持列索引,性能不如其它结构。
Table Database提供了类似RMDB的存储功能,一个主键可以有多个字段,例如,在RMDB中user表可能会有user_id、name和 password等字段,而在Table Database也提供这种支持。
Via:http://willko.javaeye.com/blog/506728
http://zhliji2.blogspot.com/2009/05/tokyo-cabinetdbm.html
下面的文章也比较精彩,对MongoDB感兴趣的可以看一看。
[译] MongoDB 入门教程:http://chenxiaoyu.org/blog/archives/242
http://www.fuchaoqun.com/2010/01/mongodb-in-action/
http://blog.chenlb.com/2010/05/mongodb-vs-mysql-query-performance.html
http://www.wentrue.net/blog/?p=772
http://www.mikespook.com/index.php/archives/524
http://hi.baidu.com/ywdblog/blog/item/44e02e9bfe5a87bfc8eaf425.html
http://www.infoq.com/cn/news/2009/09/mongodb
MongoDB 1.6 发布:http://xiexiejiao.cn/database/mongodb-1-6-release.html
http://m.cnblogs.com/66952/1673308.html
MongoDB中文介绍:http://www.mongodb.org/display/DOCSCN/Home
MongoDB文档首 页:http://www.mongodb.org/display/DOCS/Home
考虑再三还是决定回南昌买房,常州房价涨得太猛了。偏到高铁站那边去了,去年3400一平没买现在5200以上了,靠!
郁闷的是南昌最近开始城市改造,大量拆迁户拿政府8000一平方的补贴进入楼市买房,南昌房价又火起来了,看起来国家11条打压房价再次失败了,以后不相信政府了。还是早买早好,省得又白打工几年。
本来是想去北京东路附近买的,方便以后亲戚窜门,但是他妈的不是一般的贵,一个楼盘花了1万块预定,号不太好,一个小时后就剩1楼了,妈的!最后看了青云谱包家花园附近的房子,可是房子都只有一楼和顶楼,我的天啊,而且还一天一个价。后来没办法,只能订了城东一套房子。94平方44万,首付得3成,靠,已付了5万块的定金!这次中秋回南昌去交首付和办理贷款。
接下来的几年就要天天想着还贷了。最近几年不再关注楼市的事,太他妈的不是人干的事了。他妈的共产党你真心想把房价降下来就放剂猛药不就得了,听说欧洲不允许有空房,空房一定年限后国家收回分给没房的人住。现在国家只是控制控制银行贷款,但是炒房投机的人人,人家直接全额买可以么。靠!
目前linux版本已正常工作,上周windows版本也存在内存泄漏问题,找了半天才发现是因为数组过界引的
另今天移值到linux平台,都是用gcc windows下正常 linux下就内存泄漏,怪事。。不过还好找到了问题所在。
另新加了一个程序自动从文本文件里读取验证码的功能,方便linux在nohup下运行,无需担心验证码输入的问题。
目前程序挂服务器上进行测试,如不稳定继续修改!
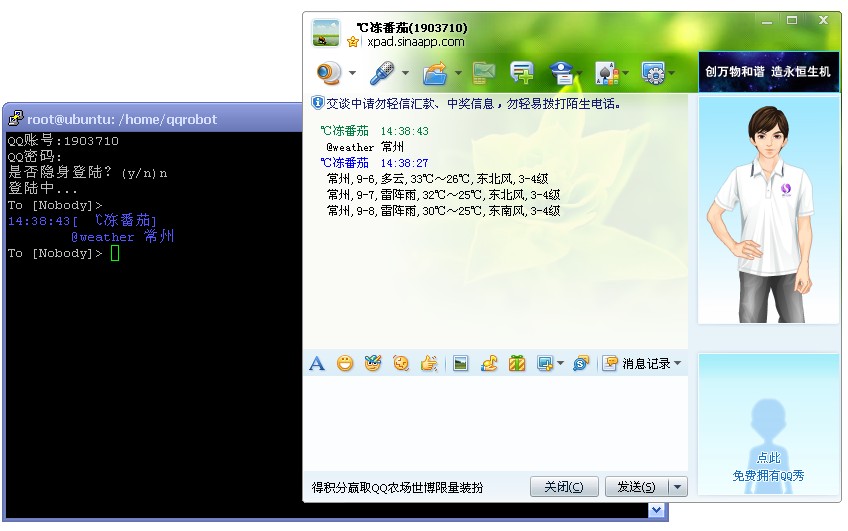
qq通信服务端是在myqq上二次开发,所以支持linux/windows双平台
主控程序采用php开发
主要的功能是:
查ip地址、查电话归属地、查天气预报、查pr值、在线翻译等都是些常用的功能
目前windows下正常,准备着手迁移至linux平台,还好机器人程序的主要库libcurl是跨平台的。

今天在公交车上,由于拥挤一男一女发生了碰撞。
时髦女郎回头飞眼道:“你有病啊?”
男子觉得莫名其妙回道:“你有药吗?”
车上人窃笑!
女子觉得生气回道:“你有精神病啊?”
男子冷面对道:“你能治啊?”
全车人爆笑!
公交司机停车,趴在方向盘上大笑!
这是珠江路上上班的朋友遇见的
公交车上超挤,有一女人站在门口,
从车后面挤过来一个GG要下车,
跟那女的说了一句“让一下,下车”,那个女滴木有动。
GG挤过去时就踩到她了。
结果那女人好厉害的,不停的骂“神经病啊你!神经病啊你!~~”,还超大声,搞得全车都看呀。
GG一直木有说话,下车时忍不了了,回头对那女人说,“复读机呀你!”
全车人暴笑~!
后边有几个搞笑的小孩,不停的伴演刚才的一幕,
甲说“你神经病呀你!。。。。。乙说“你复读机呀你”。。。。。。 新浪乐居论坛:
全车人暴笑~!
后来,有个小MM也要下车,挤过去怯怯滴说“偶~偶~偶想下去,偶不是神经病~!”
全车人再次暴笑~!
那个女人木有说话,可是从边上飘来一句话“你是不是没电了”
全车人暴笑不止~!
mongodb是nosql的典型了,采用是json类似的存储格式
mongodb官网下载windows平台下的服务端: http://www.mongodb.org/downloads
mongodb的php驱动:http://github.com/mongodb/mongo-php-driver/downloads
mongodb下载后,解压到D盘,最终地址是:D:\mongodb\bin
php驱动 php_mongo.dll 解压至php的ext文件夹下,然后修改php.ini,添加 extension=php_mongo.dll 新建数据库存放文件夹 D:\mongodb\db
mongodb的启动:
在命令行输入 D:\mongodb\bin\mo\mongod –dbpath D:\mongodb\db
到这里,mongodb已启动,打开http://127.0.0.1:28017/ 可以看到mongodb运行情况
为了方便以后每次不必启动mongod,可以把mongod注册成windows服务
mongodb php使用方法:
3 用PHP操作Mongondb
简单列子 //这里采用默认连接本机的27017端口,当然你也可以连接远程主机如192.168.0.4:27017,如果端口是27017,端口可以省略
$m = new Mongo();
// 选择comedy数据库,如果以前没该数据库会自动创建,也可以用
$db = $m->comedy;
//选择comedy里面的collection集合,相当于RDBMS里面的表,也-可以使用
$collection = $db->collection;
$db->selectCollection("collection");
/* —– 添加一个元素 —–*/
$obj = array( "title" => "Calvin and Hobbes", "author" => "Bill Watterson" );
$collection->insert($obj); //将$obj 添加到$collection 集合中
/* —– 添加另一个元素 —–*/
$obj = array(
"title" => "XKCD",
"online" => true
);
$collection->insert($obj);
$cursor = $collection->find();
//遍历所有集合中的文档
foreach ($cursor as $obj) {
echo $obj["title"] . "\n";
}
//断开MongoDB连接
$m->close();
3.2 常用函数
$query = array( "i" => 71 ); $cursor = $collection->find( $query ); // 在$collectio集合中查找满足$query的文档 while( $cursor->hasNext() ) { var_dump( $cursor->getNext() ); } $collection -> findOne(); //返回$collection集合中第一个文档 $collection -> count(); //返回$collection集合中文档的数量 $coll->ensureIndex( array( "i" => 1 ) ); // 为i “这一列”加索引 降序排列 $coll->ensureIndex( array( "i" => -1, "j" => 1 ) ); // 为i “这一列”加索引 降序排列 j升序
3.3 查询时,每个Object插入时都会自动生成一个独特的_id,它相当于RDBMS中的主键,用于查询时非常方便
如:
<?php $person = array("name" => "joe"); $people->insert($person); $joe = $people->findOne(array("_id" => $person['_id'])); ?>
昨天写了个php程序,给mysql插入随机的文章数据,仿照真实文章,中文数据,主要是测试在100w级数量时查询上的优化及测试mysql内置的全文检索与其它类似全文检索引擎的差距等。总数据量:article 101w左右 user表10w左右,总计占用硬盘2G左右
今天开始测试在海量数据查询时的优化手段
最后附上一截图